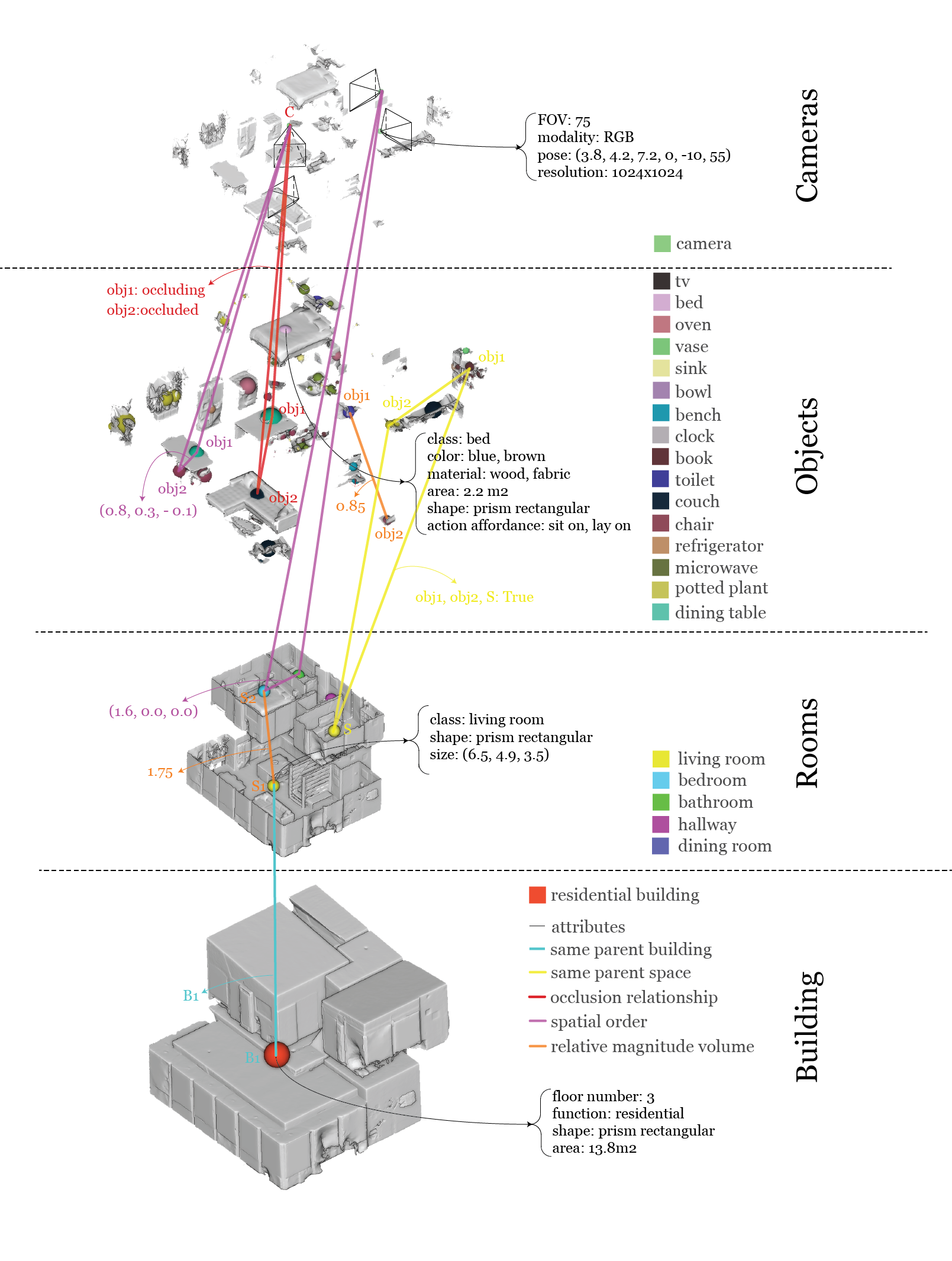
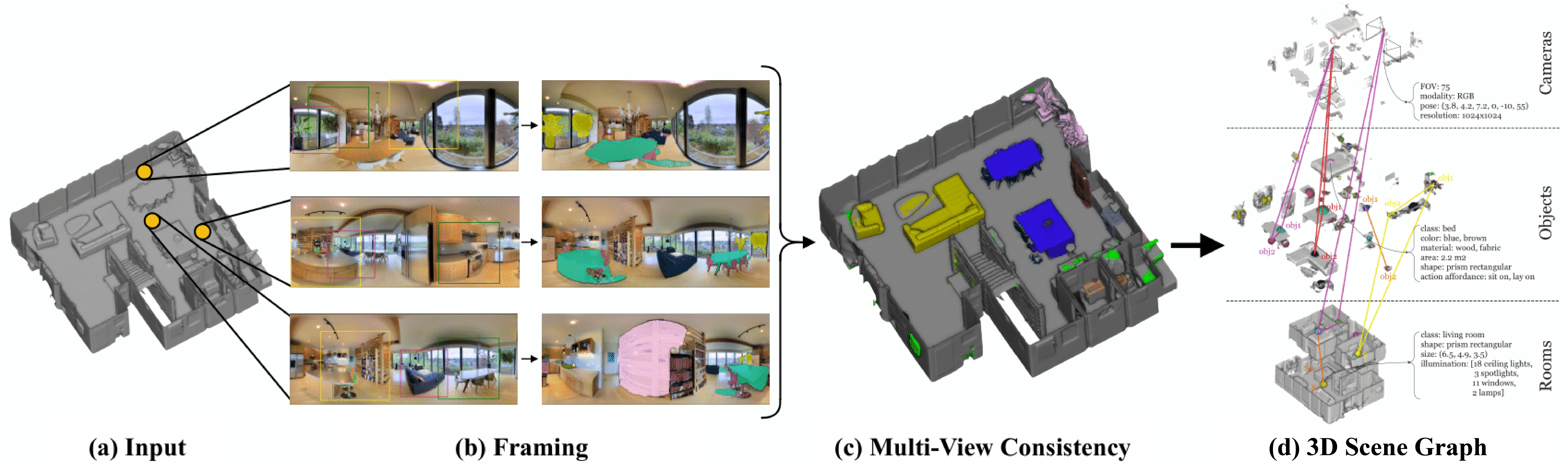
[1] Xia, F., Zamir, A. R., He, Z., Sax, A., Malik, J., & Savarese, S. (2018). Gibson env: Real-world perception for embodied agents. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 9068-9079).

 |
 |
 |
 |
 |
 |
 |
| Iro Armeni | Zhi_Yang He | JunYoung Gwak | Amir R. Zamir | Martin Fischer | Jitendra Malik | Silvio Savarese |
| Stanford University - CIFE, SVL | Stanford University - SVL | Stanford University - SVL | Stanford University - SVL UC Berkeley - BAIR |
Stanford University - CIFE | UC Berkeley - BAIR | Stanford University - SVL |
| Next: | Annotations for Gibson's large split to follow. |
| Feb 18th 2020: | Released code to generate automatic annotations given a 2D detector, as well as code to compute attributes and relationships. |
| Jan 22nd 2020: | Released annotations for Gibson's medium split. |
| Oct 8th 2019: | Released annotations for Gibson's tiny split. |